
Hogarama als Learning Friday Projekt und automatische Bewässerungsanlage hat während ihrer Lebenszeit bereits einige Veränderungen hinter sich gebracht. Das Ergebnis der bisherigen Verwandlung kann im Artikel Hogarama und der Second System Effect nachgelesen werden. Nun ist es wieder mal so weit, im Hogarama Projekt wird wieder experimentiert. Diesmal soll die ActiveMQ (Red Hat AMQ Broker) durch Apache Kafka (Red Hat AMQ Streams) ersetzt werden und Hogarama, ähnlich wie die Hauptperson Gregor Samsa in Kafka’s “die Verwandlung”, grundlegend verändern. Welche “Verwandlungen” tatsächlich stattgefunden haben, wie wir dabei vorgegangen sind und ob das Ergebnis ein furchterregender Käfer oder ein wunderschöner Schmetterling geworden ist, werden wir euch in diesem Blogeintrag näherbringen.

- Hogarama
- Learning Friday
Hogarama bekommt mit Apache Kafka eine Verwandlung
Hogarama hat schon einige Veränderungen hinter sich. Gelingt es den Geparden Hogarama mithilfe von Apache Kafka in einen schönen Schmetterling zu verwandeln oder wird es doch ein furchterregender Käfer?
Funktionsweise in a Nutshell
Siehe das bis dato gültige Hogarama-Architekturbild. Den aufmerksamen Leser:innen fällt dabei vielleicht auf: ja, es ist etwas zu tun, Contributors welcome 😉
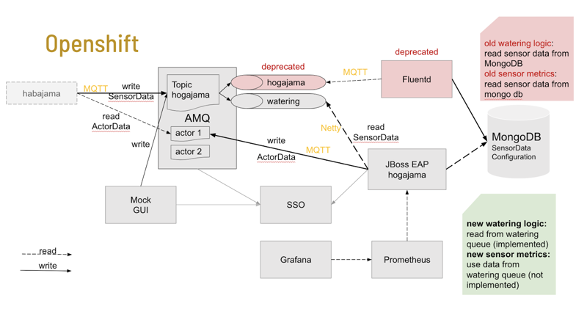
Unser Ziel
- Installation des Kafka-Clusters in AWS OpenShift
- Hogarama: Ersatz der Kommunikation zur Bewässerungs-Komponente durch Kafka
- Hogarama ist immer lauffähig (Operation am offenen Herzen)
Wen es besonders interessiert, warum wir die bestehende AMQ Anbindung ändern wollen und welche Vorteile wir uns von Kafka erwarten, der möge zum Kapitel “Change a running System, warum Kafka?” springen, für die Praktiker folgt eine Einführung der Kafka Installation.
Installation des Kafka-Clusters in OpenShift
Über den Operator Hub versuchten wir zuerst mittels Strimzi Operator unseren Kafka-Cluster zu betreiben. Leider waren weder die Zookeeper Pods (für die Konfiguration von Kafka in Verwendung), noch die Kafka-Pods an sich sehr stabil und waren von permanenten Pod-Restarts geplagt. Da dies kein geeignetes Umfeld für das Puppenstadium unserer Verwandlung ist, haben wir diesen Ansatz relativ schnell wieder verworfen und haben uns AMQ Streams (dem Kafka Produkt von Red Hat) zugewandt. Das Ergebnis mit AMQ Streams war leider nicht weniger instabil. Im Zuge der Fehleranalyse mussten wir feststellen, dass unser OpenShift 4 Cluster sich in einem Limbus zwischen zwei verschiedenen Versionen befindet und im Allgemeinen nicht unbedingt einem produktionsreifen, stabilen Zustand befindet. Dies ist jedoch ein Problem für die Zukunft und soll uns in unserer Verwandlung nicht aufhalten.
→ Wir verwenden AMQ Streams über den Operator Hub
Ersatz der Kommunikation durch Kafka
Da wir uns als Ziel gesetzt haben rückwärtskompatibel zu sein und alle bisherigen Clients ihre Sensorwerte an unsere AMQ schickten und Pumpevents zur Bewässerung von dort abholten, wollten wir die AMQ nicht restlos streichen. Deswegen entschieden wir uns für die folgende Architektur-Änderung:
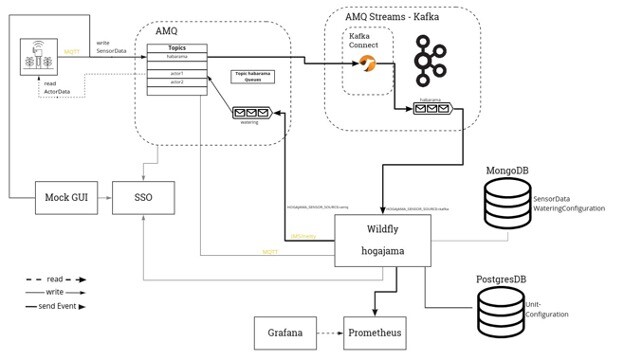
Kafka bot uns die Möglichkeit, die Habaramas weiter mit der AMQ kommunizieren zu lassen. Über Kafka-Connectoren verknüpften wir unseren Kafka-Cluster um die Daten aus der AMQ abzuholen. Der Wildfly wiederum holt sich die Daten nun nicht mehr aus der AMQ, sondern aus dem Kafka-Cluster. Diese Connectoren mussten wir nicht selbst implementieren, da diese schon als OpenSource zur Verfügung stehen. Wir verwenden daher einen Camel Kafka Connector um Kafka mit der AMQ zu verknüpfen. Nach viel Trial and Error haben wir es schlussendlich geschafft unseren Connector online zu stellen und erfolgreich Nachrichten aus der AMQ abzuholen und an den Kafka-Cluster zu schicken.
Hogarama ist immer lauffähig?
Durch das Verwenden der Connectoren war es uns möglich, im ersten Schritt den bisher verwendeten JBoss EAP 7 die Daten weiterhin von der AMQ abholen zu lassen, während diese parallel schon am Kafka-Cluster landeten. In einem weiteren Schritt wurde die Applikation umgestellt, damit diese die Daten von Kafka bezieht. Dafür verwenden wir die Reactive Messaging API des Eclipse Microprofiles. Leider mussten wir feststellen, dass JBoss EAP dieses noch nicht unterstützt und wir auf die neueste Version des Upstream Projektes – Wildfly ( 23.0.1.Final)- umsteigen müssen.
Anbinden von Hogajama an den Kafka-Cluster
Durch die Verwendung der Reactive Messaging API des Eclipse Microprofiles war es uns nach der Konfiguration möglich über ein paar simple Annotationen die Messages aus Kafka abzuholen, wie im folgenden Code-Snippet ersichtlich ist:
import javax.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
@ApplicationScoped
public class WateringKafkaEndpoint {
//...
@Incoming("habarama-in")
public void onMessage(String message) {
//...
}
}
Jedes mal, wenn am Kafka Topic, welches als “habarama-in” konfiguriert ist, eine Nachricht verfügbar ist, wird diese von der onMessage-Methode verarbeitet.
Testdaten für den Kafka-Cluster
Da wir nicht ständig auf neue Daten aus den Habarama-Sensoren warten können um Änderungen zu testen, haben wir die bestehende Mock-CLI adaptiert, sodass diese auch Daten direkt an den Kafka-Cluster senden kann, ohne dass dafür eine AMQ benötigt wird. Bei der Umsetzung dieser Funktion haben wir die Producer API von Kafka selbst verwendet.
Tooling
Um zu Überprüfen ob das Kafka Topic korrekt angelegt wird und ob die Message richtig zugeordnet werden wird das Open-Source Tool Kafdrop verwendet. Kafdrop ist ein einfaches Tool zum Anzeigen von Kafka Brokers, Topics, Messages, Consumers Groups, und zum Erstellen von neuen Topics. Ein weiterer praktischer und für Entwickler freier Kafka-Client ist Conduktor.
Ist die Verwandlung geglückt?
Die Verwandlung zum wunderschönen Schmetterling ist uns nicht vollständig, aber doch zum Großteil geglückt!
- Kafka ist in OpenShift installiert (über AMQ Streams)
- Das Lesen der Sensordaten verwendet Kafka statt AMQ
- AMQ ist vollständig durch Kafka ersetzt
- Hogarama war “meistens” lauffähig*
*Zumindest wurden die Produktionsprobleme durch Kafka nicht verschlechtert 😉
Wir haben durch unsere Änderungen derzeit auch nur an der Oberfläche der Möglichkeiten, die ein Kafka bietet, gekratzt. Es gibt hier noch eine Menge zu erkunden, wie etwa KStreams und KTables um nur zwei der vielen Möglichkeiten zu nennen. Weiters haben wir unsere Applikation auch noch nicht darauf ausgelegt, dass mehrere Consumer gleichzeitig vom selben Kafka-Cluster lesen. Auf jeden Fall haben wir mit unserem Projekt eine gute Ausgangsbasis für weitere Learning-Friday Projekte zum Thema Kafka geschaffen.
Change a running System, warum Kafka?
Besonders während Corona-Zeiten leistet Hogarama gute Dienste bei der Bewässerung unserer Büropflanze.
Warum also sollten wir die scheinbar funktionierende Konfiguration ändern und Apache Kafka einführen? Weil eben nicht alles so funktioniert, wie wir uns wünschen würden.
Lokale Durchschnittsberechnung
Um die eintreffenden Sensorwerte, für die Berechnung ob gewässert werden soll, zu glätten, mitteln wir die letzten Sensorwerte. Solange nur ein Server läuft, ist das kein Problem. Sobald aber mehrere Server laufen werden die Sensorwerte auf die Server aufgeteilt. Wenn die Mittelwertberechnung nur einen lokalen Cache verwendet, dann gehen der Mittelwertberechnung Werte verloren. Besser wäre es, wenn die Sensorwerte für einen Sensor immer am selben Server landen würden. Damit gingen auch einem lokalen Cache keine Werte verloren. Das funktioniert mit Kafka indem sogenannte Partition Keys mit der Sensorid befüllt werden.
Queue oder Topic
Für die eintreffenden Sensorwerte hatten wir zwei unabhängige Verarbeitungen. Zum einem die Berechnung der durchschnittlichen Feuchtigkeit um die Bewässerungspumpe zu steuern, zum anderen konfigurierten wir einen Fluentd-Client, der die Sensorwerte in einer Mongo-DB speichert (siehe ursprüngliches Architekturbild). Daher verwendeten wir ein Topic, bei dem jeder Client alle Sensordaten bekommt. Das Problem entsteht, wenn wir z.B. Fluentd skalieren. Dann wir jeder Sensorwert zweimal in die Datenbank eingefügt (oder es gibt duplicate Key Fehler). Auch die Bewässerungslogik führt bei einem Topic und mehreren Hogajama-Instanzen zu Doppeltbewässerung.
Würden wir eine Queue verwenden, würde die Nachricht nur entweder an Fluentd oder an die Bewässerung schicken. Das geht natürlich auch nicht. Das Problem kann man mit AchtiveMQ lösen indem man ein Topic konfiguriert und für jeden Clienttyp (Fluentd und Hogajama) eine Queue anhängt. Damit kann man die Clients skalieren.
Diese Konfiguration auf Serverseite ist doch etwas kompliziert. Kafka hat den Vorteil, dass man dieselbe Funktion mit einfacherer Konfiguration auf Clientseite erhält und damit nicht einen zentralen Server ändern muss. Bei Kafka gibt es Clientgruppen. Jede Clientgruppe erhält alle Nachrichten, aber innerhalb einer Clientgruppe werden die Nachrichten aufgeteilt. Fluentd und Hogajama werden einfach einer eigenen Clientgruppe zugeteilt und das Problem ist gelöst.
Und Außerdem
Kafka hat noch weitere Eigenschaften, die zwar für Hogarama nicht so wesentlich sind, aber für andere Projekte sehr hilfreich sein können. Z.B. dass die Nachrichten für längere Zeit persistiert werden oder dass Kafka von Grund auf für einen Cluster-Betrieb entwickelt wurde. Vor allem aber, dass Kafka cool ist und wir es einfach mal ausprobieren wollten.


