Unsere Ziele
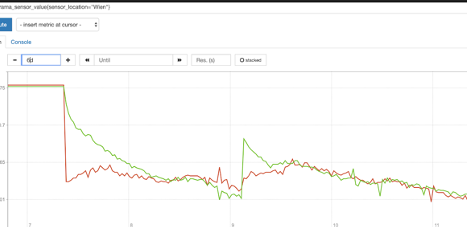
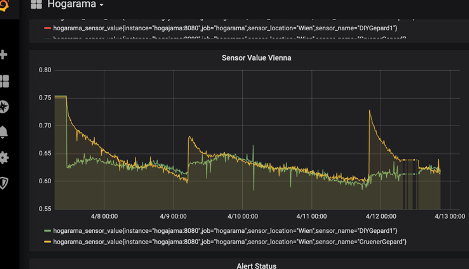
Damit wir nicht nur einen künstlichen Prototypen bauen, den wir nachher wieder wegwerfen, war unser Plan Prometheus in Hogarama zu integrieren. Zusätzlich zum vorhandenen, zugegebenermaßen mit Problemen behafteten, Hogarama-GUI sollten die Sensordaten in Prometheus angezeigt werden. Wenn möglich schneller als im alten GUI.